There is a growing need for accurate and scalable techniques to understand, search, and retrieve satellite Earth Observation (EO) images from massive archives, such as the Copernicus archives. In the era of big data, the semantic content of satellite data is much more relevant than traditional keywords or tags. To meet the increasing demand for automation, image search engines that extract and utilize the content of satellite images are necessary, leveraging cutting-edge technologies and advancements in Natural Language Processing (NLP), Machine Learning (ML), and Computer Vision (CV) applied to Earth Observation challenges (NLP4EO). In other words, there is an emerging need to go beyond traditional queries of EO data catalogues, which are based on technical image metadata (such as location, time of acquisition, and technical parameters), and to enrich the semantic content of image catalogues. This will enable a brand new class of query possibilities powered by the combination of NLP (to understand the query and describe the content of the data) and CV (to massively annotate data and implement multi-modal text-to-image and image-to-image searches). Currently, search engines with 'query by content' functionalities do not exist within DIAS platforms or other satellite EO data platforms. Moreover, a Digital Assistant capable of understanding complex requests related to geospatial data searches could significantly expand the dimensions used to query EO data archives. It could also include advanced capabilities to understand and process user requests, select the most suitable workflow to satisfy these requests, autonomously execute processing on EO and non-EO data, and ultimately answer the user's initial question. In this scenario, the development of a precursor demonstrator of a Digital Assistant will adhere to the following high-level objectives:
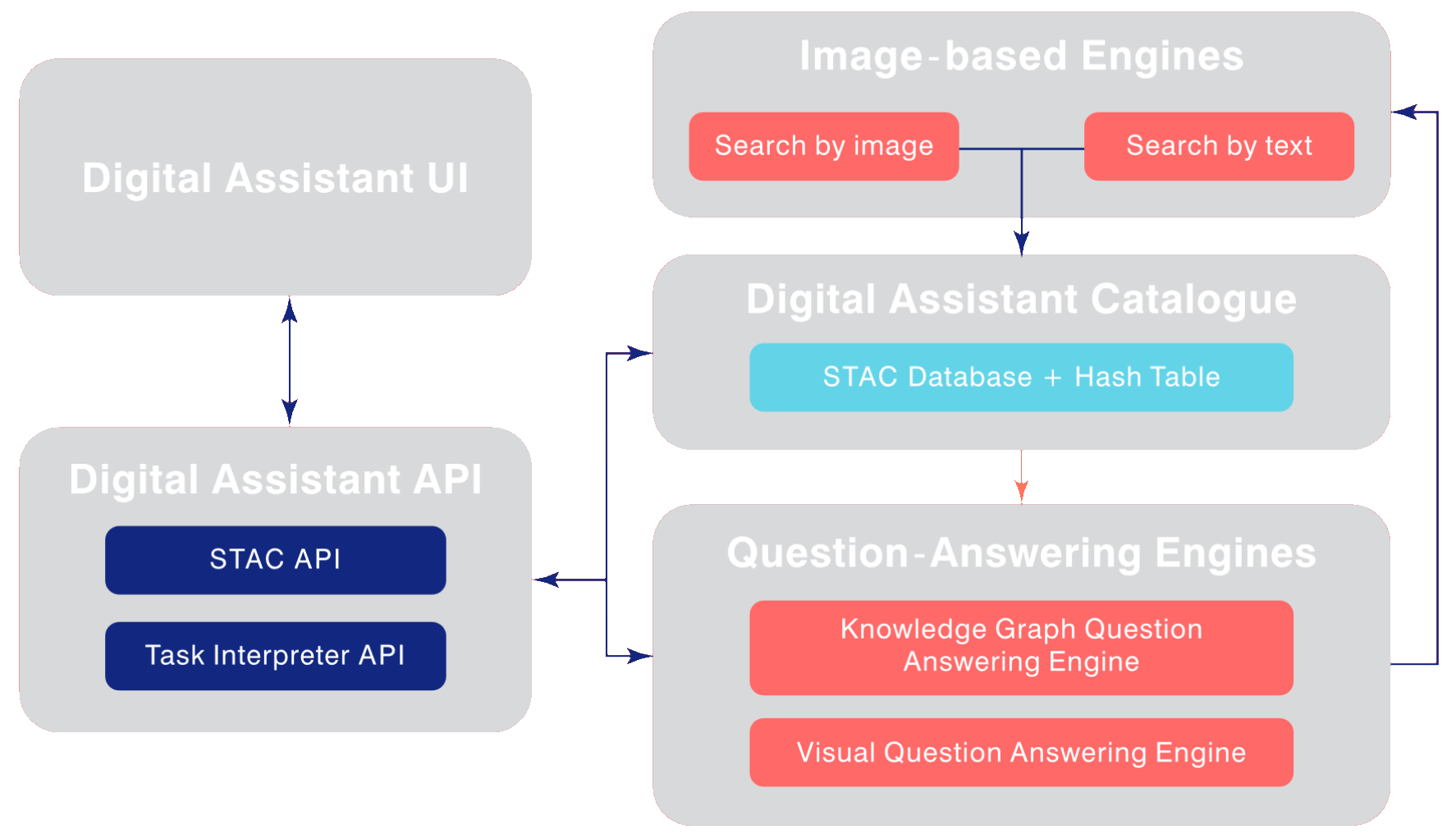
The digital assistant's high-level architecture is structured into three main components:



