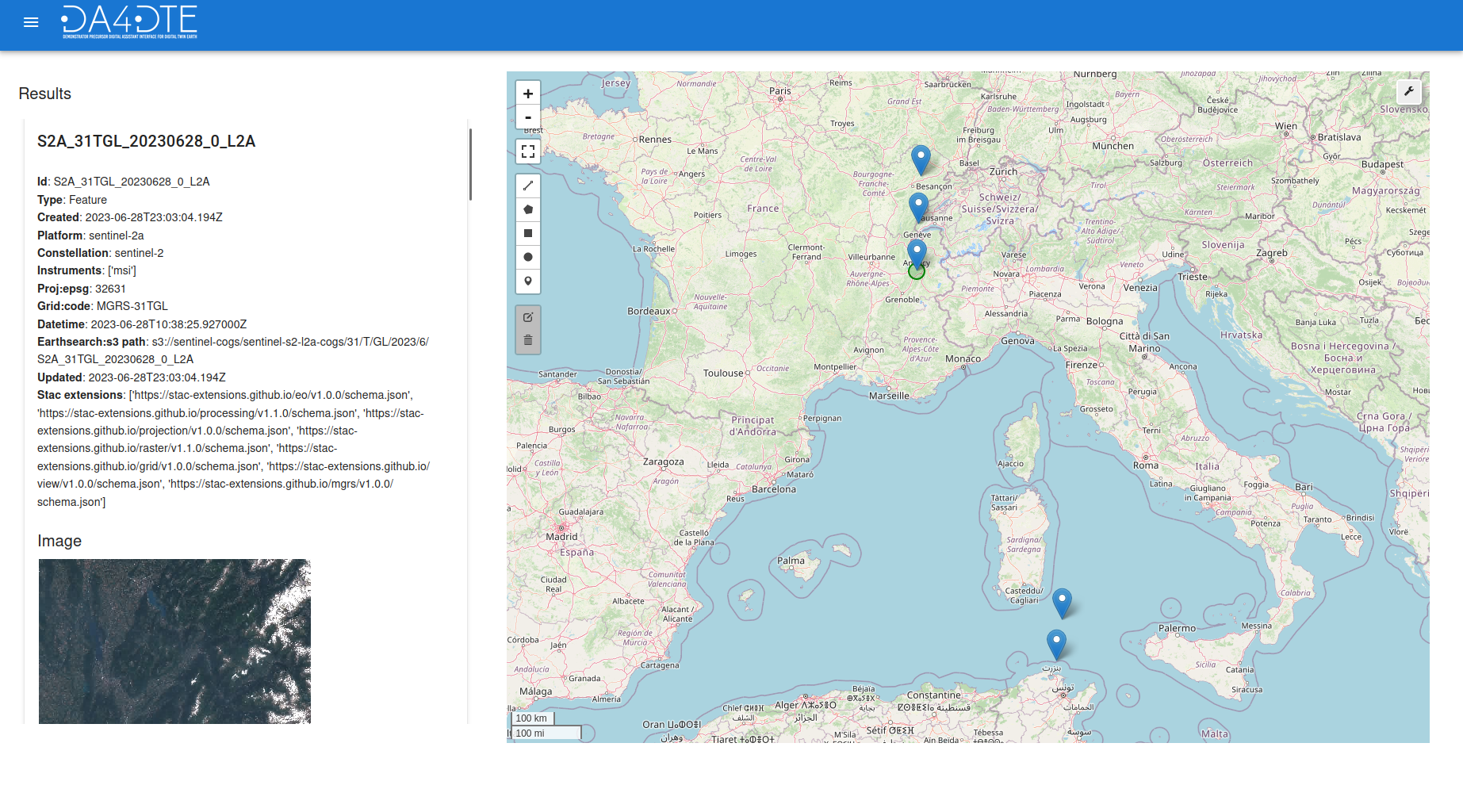
The Knowledge Graph Question Answering (KGQA) engine accepts questions in natural language (English) that request satellite images meeting specific criteria and returns links to such datasets. The questions can refer to image metadata as well as geographic entities, both of which are included in the target knowledge graph.
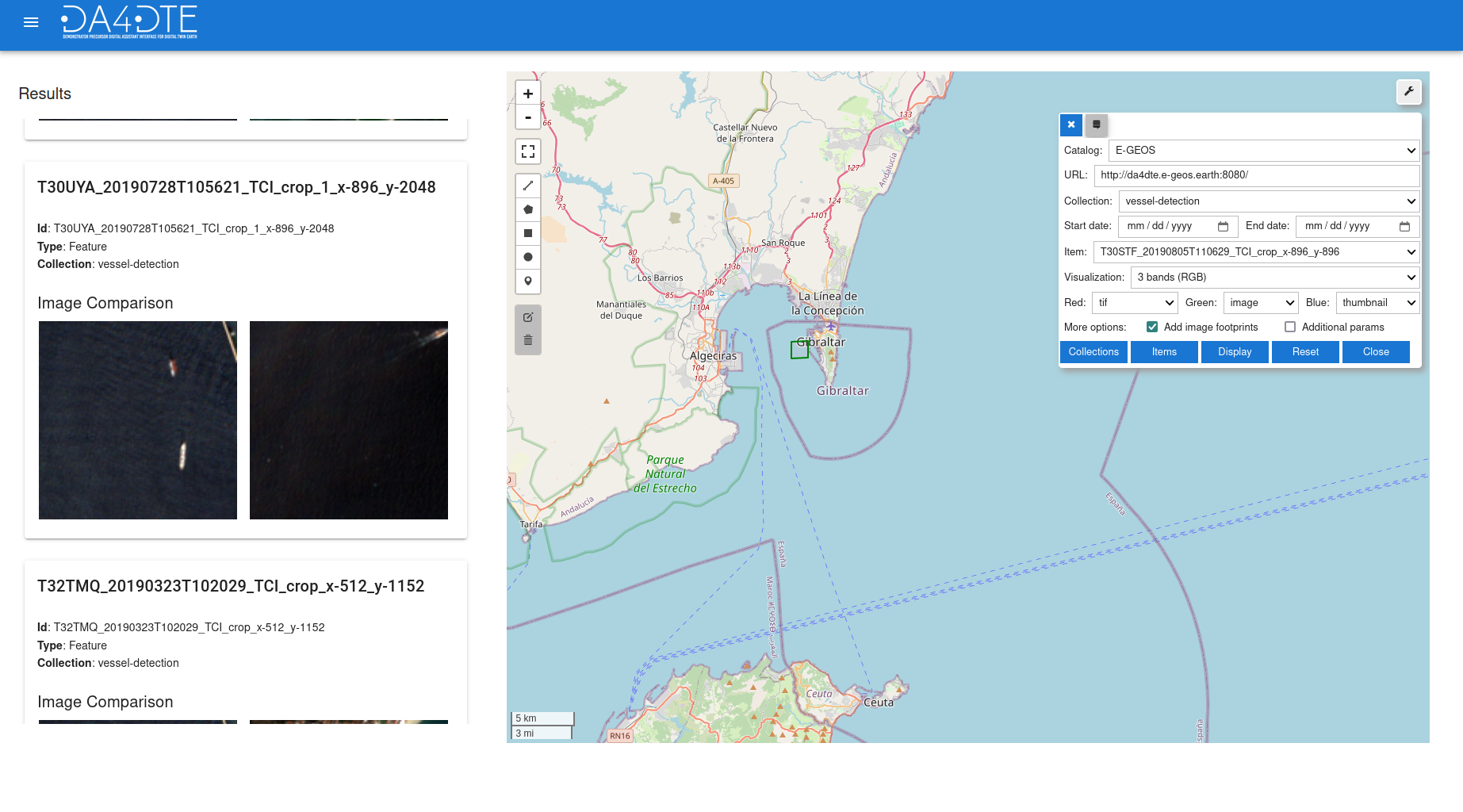
The Search by Image engine takes a query image and computes the similarity function between the query image and all archive images to find the most similar images in a scalable way. We developed this engine based on the self-supervised DUCH and CM-MAE methods.
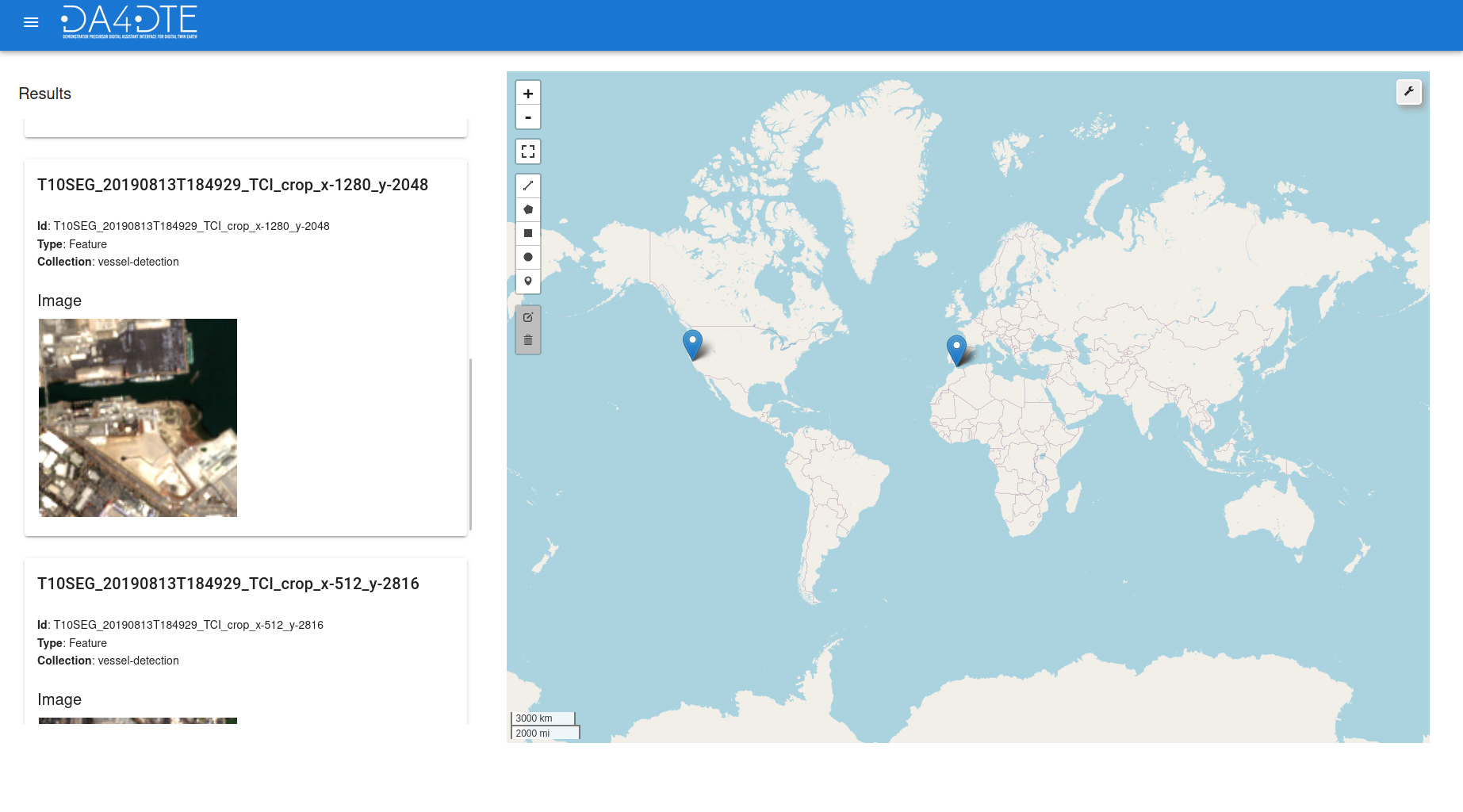
The Search by Caption engine takes a text sentence to search for images, achieving cross-modal text-image retrieval. We developed this engine by adapting the self-supervised DUCH and CM-MAE methods to be operational on text-based queries.
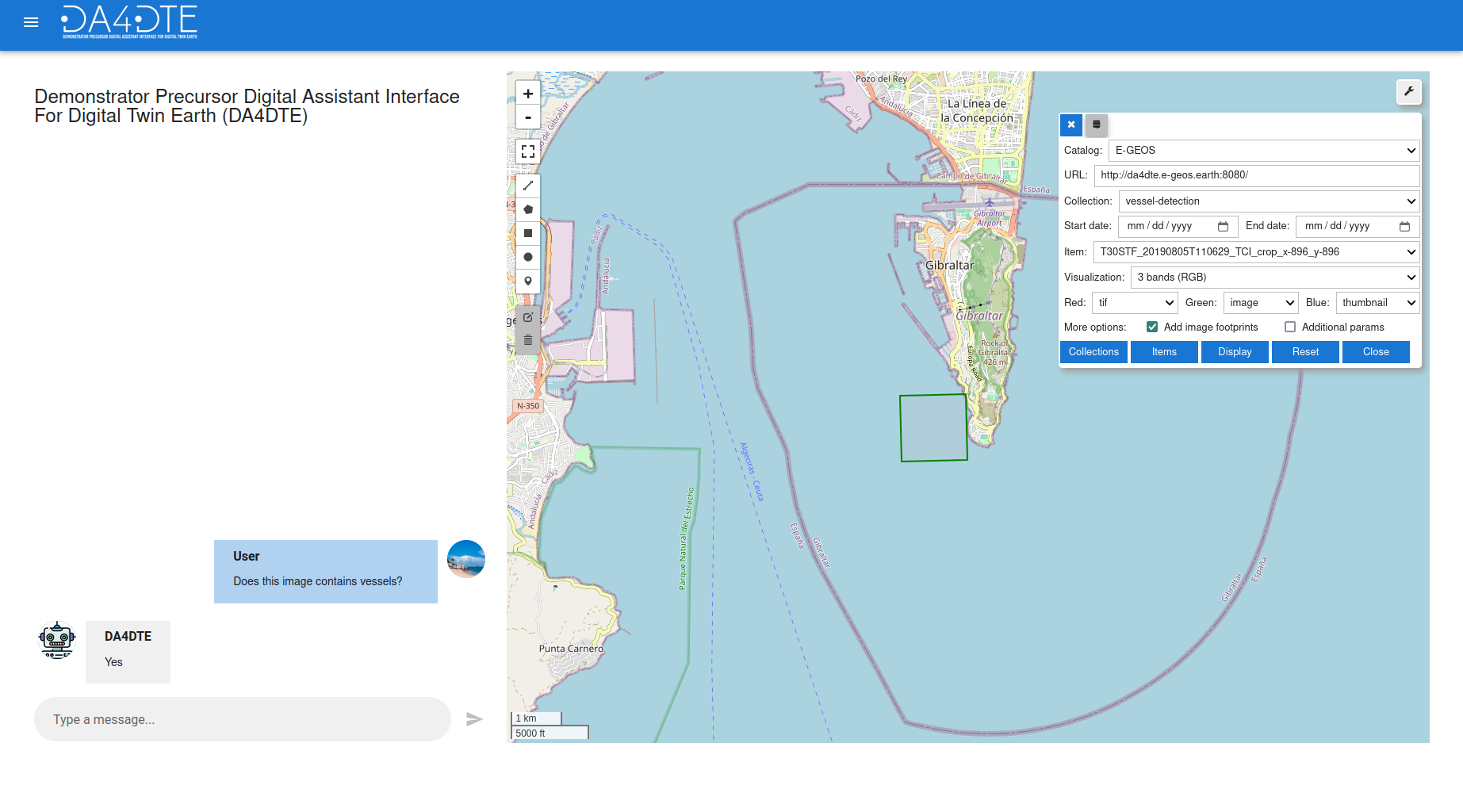
The Visual Question Answering (VQA) engine allows users to ask questions about the content of remote sensing (RS) images in a free-form manner, extracting valuable information. In this context, an efficient and accurate VQA model called LiT-4-RSVQA, based on a lightweight transformer architecture, has been developed.
This is a demonstration of a prototype Digital Assistant Interface, designed to showcase its potential functionalities. To ensure you experience all its features correctly, we strongly suggest following the provided manual. While you may explore different uses of the Digital Assistant, please be aware that deviations from the recommended guidelines may result in unpredictable behavior or may not work properly.



